





























Understanding of Apache kafka metrics for monitoring
- 1. Apache Kafka 모니터링을 위한 Metrics 이해 1 박상원
- 3. 3 현재 상황을 파악하고 이상 상태를 감지하여 대응하는 활동 장애 방지 성능 개선
- 4. 4 어떻게 현재 상황을 파악할 수 있을까?
- 5. 5
- 6. 6 내 업무에 최적화된 모니터링을 하려면? 다른 Metric과 연계한 새로운 지표 생성 측정된 지표에 따른 Alarm 등의 업무 자동화
- 8. 8 수집할 JMX Metrics을 선택
- 9. 9
- 10. 10 어떤 정보를 모니터링 해야 할까? (클러스터 안정성, 메세지 적시성, 확장성 고려 )
- 11. 11 적시성 Producer에서 Consumer로 지연 없이 전달되는가?
- 12. 12 Producer Consumer Broker Broker Broker ü 얼마나 빨리/많이 보내고 있는가? ü Producer에서 Consumer까지 얼마나 빨리/많이 전달되는지 확인 필요 ü 얼마나 빨리/많이 수신하고 있는가? ü Producer와 Consumer 양쪽의 요청을 얼마나 빨리/많이 처리하고 있는가? 적시성을 위해 확인해야 할 Metrics 유형은?
- 13. 13 Producer Metrics (Kafka 0.8.2 이후) Metric Comments Alert request-rate • 초당 요청(to broker) 건수 response-rate • 초당 응답(from broker) 건수 요청과 응답 비율이 유사해야 함. outgoing-byte-rate • 초당 Broker로 전송한 bytes 처리량 개선 확인 io-ratio • I/O 작업을 위해 I/O thread가 사용한 시간 비율 io-wait-ratio • I/O thread가 waiting에 소요한 시간 비율 https://www.confluent.io/blog/optimizing-apache-kafka-deployment/
- 14. 14 https://blog.serverdensity.com/how-to-monitor-kafka/ Metric Comments Alert records-lag-max • 최신의 메세지 offset값과, consumer가 읽어간 offset값의 최대 차이 • 값이 증가한다면, consumer group이 데이터를 빠르게 가져가지 못함 MaxLag > (자체 기준) fetch-rate • Broker에 초당 요청(request call)하는 회수 • 만약 consumer가 중지되었다면, 0으로 낮아질 것이다. fetch-rate < 0.5. records-consumed-rate • 초당 읽은 메세지(record) 개수 bytes-consumed-rate • 초당 읽은 byte size commit-rate • Consumer가 kafka에 offset을 commit한 비율 (초당 commit수) Consumer Metrics (Kafka 0.9.0.0 이후) 전체 Consumer, Consumer Group, Topic 별 구분하여 모니터링 가능
- 15. 15 https://blog.serverdensity.com/how-to-monitor-kafka/ Metric Comments Alert MessagesInPerSec • 초당 유입되는 메세지 count (많을 수록 처리성능이 높음) • (kafka.server: type=BrokerTopicMetrics) BytesInPerSec / BytesOutPerSec • 초당 유입 & 유출 되는 byte (많을 수록 처리성능이 높음) • (kafka.server: type=BrokerTopicMetrics) RequestsPerSec • 초당 요청 건수 {Produce|FetchConsumer|FetchFollower} • (kafka.network: type=RequestMetrics) TotalTimeMs • 하나의 요청을 처리하는데 소요된 전체 시간 {Produce|FetchConsumer|FetchFollower} • 구간별로 분할하여 시간 측정 가능 • (kafka.network: type=RequestMetrics) Broker Metrics Cluster, Broker, Topic 단위로 구분하여 모니터링 가능
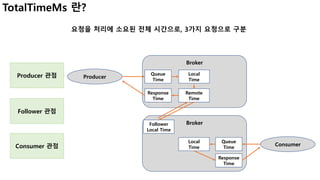
- 16. 요청을 처리에 소요된 전체 시간으로, 3가지 요청으로 구분 TotalTimeMs 란? Producer Broker Producer 관점 Queue Time Local Time Broker Remote Time Follower Local Time Response Time Consumer 관점 Consumer Queue Time Response Time Local Time Follower 관점
- 17. 17 TotalTimeMs이 너무 오래 걸리면, Bottleneck이 어디서 발생하는지 상세 metrics 확인 Metric Comments RequestQueueTimeMs • 요청 큐에서 기다리는 시간을 producer, consumer fetch, follower fetch별로 측정 • 높은 값(대기 시간이 길어지는 현상)은 I/O thread가 부족하거나, CPU 부하 예상 • (kafka.network:type=RequestMetrics) LocalTimeMs • 전달된 요청을 leader에서 처리하는 시간. (leader가 local data 처리) • 높은 값은 disk i/o가 낮음을 의미 • (kafka.network:type=RequestMetrics) RemoteTimeMs • 요청이 Folllower를 기다리는 시간 • 높은 값은 NW 연결이 늦어짐을 의미 • Fetch 요청에서 이 값이 높은 것은, 가져올 데이터가 많지 않음을 의미할 수 있음 • (kafka.network:type=RequestMetrics) ResponseQueueTimeMs • 요청이 응답 큐에서 대기하는 시간. • 높은 값은 NW thread가 부족함을 의미. • (kafka.network:type=RequestMetrics) ResponseSendTimeMs • Client의 요청에 응답한 시간. • 높은 값은 NW thread 또는 CPU가 부족하거나, NW부하가 높음을 의미 • (kafka.network:type=RequestMetrics) TotalTimeMs 란? (세부 Metrics 확인)
- 18. 18 안정성 데이터 유실없이 중단 없는 서비스를 할 수 있는가?
- 19. 19 Broker (Active Controrller) ü 데이터 처리의 핵심인 Partition이 장애없이 정상적으로 운영되는가? ü Server의 불필요한 Disk I/O 가 발행하지 않는가? 안정성을 위해 확인해야 할 Metrics 유형은? Broker Broker Partition (Leader) Partition (Follower) Partition (Follower) 장애 발생시
- 20. 20 Kafka Server에서 Swap이 발생하면, Disk I/O가 발생하여 성능에 영향 https://blog.serverdensity.com/how-to-monitor-kafka/ Swap이 발생하는 원인 • Kafka 구동시 설정한 Heap Memory를 초과하는 경우 • 데이터를 swap(Disk) 공간으로 복사하게 됨. (프로그램 이 중지되지 않도록 하는 역할) • 한번 swap공간으로 이동하면, 다시 메모리로 돌아오게 할 수 없다. à 성능 저하 유발 Swap 발생 조건 변경 • vm.swappiness • 메모리에서 swap으로 이동을 언제 할지 결정 • vm.swappiness = 10 à 메모리 사용률 90% 이상일 때 • Kafka 성능을 극대화 하려면, • vm.swappiness = 0 à 메모리에서만 처리하도록 설정 System Metrics (Swap usage)
- 21. 21 ü 데이터 처리의 핵심인 Partition이 장애없이 정상적으로 운영되는가? Topic 생성, leader 선출 및 복제가 완료된 상태 Partition의 생성 및 장애 시 상태 변화 Topic 생성시 상태 변화 NewPartition https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Controller+Internals NewReplica NewReplica OnlinePartition (Leader) OnlineReplica (Follower) OnlineReplica (Follower) ISR ISR ISR Broker 장애 시 상태 변화 OfflinePartition (Leader) OnlineReplica (Follower) OnlineReplica (Follower) OSR ISR ISR 신규 Leader 선출 OfflinePartition (follower) OnlinePartition (Leader) OnlineReplica (Follower) OSR ISR ISR 장애 발생 장애 Broker의 partition은 OfflinePartition으로 표시 신규 leader가 선출되고 정상 서비스 가능
- 22. 22 Cluster와 Partition이 정상적으로 동작하고 있는지 확인하는 Metrics https://blog.serverdensity.com/how-to-monitor-kafka/ Metric Comments Alert ActiveControllerCount • 클러스터의 Active Controller 개수 (클러스터 당 1개만 존재) • (kafka.controller: type=KafkaController) 1개가 아닌 경우 IsrShrinksPerSec IsrExpandsPerSec • Broker가 다운되었을때, 일부 partition의 ISR이 줄어든다. • Broker가 정상으로 회복하면, OSR상태에서 ISR로 복귀되는 비율 • (kafka.server: type=ReplicaManager) != 0 OfflinePartitionsCount • 쓰기가 불가능한 leader partition의 개수 (partiton의 장애) • (kafka.controller: type=KafkaController) > 0 UnderReplicatedPartitions • 데이터 복제가 완료되지 못한 partition의 개수 • 즉, 전체 partition수에서 ISR을 제외한 수 • (kafka.server: type=ReplicaManager ) > 0 UncleanLeaderElectionsPerSec • Leader election이 진행중인 비율 • 진행중이라면 그 동안 leader가 정상동작을 못하므로, 0이 되어야 함. • (kafka.controller: type=ControllerStats) != 0 Broker Metrics
- 23. 23 23 In-Sync Replica 상태가 아닌 복제본(OSR)도 leader로 선출될 수 있도록 하는 옵션 https://www.slideshare.net/ConfluentInc/when-it-absolutely-positively-has-to-be-there-reliability-guarantees-in-kafka-gwen-shapira-jeff-holoman/17?src=clipshare - 모든 replica가 ISR 상태 - B2 broker가 중지된 상태에서 B1에 새로운 메세지 입력 - B1 broker까지 다운되어 leader선출 불가 - B2의 replica는 OSR(Out of-Sync Replica) 상태 - 설정값에 따라서 leader가 될수 있으나, B1에 입력된 데이터는 유실됨 B1 B2 100 100 B1 B2 100 100 101 B1 B2 100 100 101 B1 B2 100 100 101 1 2 3 4 unclean.leader.election.enable 동작 방식
- 24. 24 처리 성능에 영향을 주는 Metrics Metric Comments Alert PurgatorySize • Broker에서 요청을 처리하지 않고, 격리시킨 요청(request)의 건수 • 어떤 경우에 이렇게 요청을 격리하나? • Produce (Producer 관점) • Request.required.acks = -1(all) 일 때, • 모든 복제가 완료되기 전까지, producer의 request는 대기(격리) • Fetch (consumer 관점) • Fetch.wait.max.ms 시간 또는 • fetch.min.bytes만큼의 데이터가 없는 경우 • (kafka.server:type=DelayedOperationPurgatory) 운영자의 설정에 따라 판단 NetworkProcessorAvgIdlePercent • 네트워크 프로세서가 유휴상태인 비율 • 낮을 수록 thread가 많은 작업을 하고 있음을 의미 • (kafka.network: type=SocketServer) < 0.3. RequestHandlerAvgIdlePercent • Request handler thread가 유휴상태인 시간의 평균 • 이 수치가 낮으면 일을 안한다는 의미. • (kafka.server: type=KafkaRequestHandlerPool) < 0.3. Broker Metrics
- 25. 25 https://blog.serverdensity.com/how-to-monitor-kafka/ Metric Comments Alert fetch-throttle-time-avg • Conusumer의 요청으로 Broker의 과도한 자원(cpu,network 등)을 사용하 는 경우, Broker가 임의로 Consumer 요청을 제한한 시간 지속 증가 시 Broker 추가 고려 join-rate • Consumer 장애로 인하여, partition이 다른 consume로 할당되는 비율 증가 시 Consumer 안정성 개선 필요 assigned-partitions • 현재 Consumer가 가지고 있는 partition의 갯수 Consumer Metrics (Kafka 0.9.0.0 이후) Consumer 관점에서 Broker의 부하를 확인하는 Metrics
- 26. Consumer와 Broker(Coordinator)간의 주기적 신호를 통해 장애 판단 Consumer 장애를 판단하는 기준은? Consumer의 신호 확인 (session.timeout.ms, max.poll.interval.ms ) • Consumer가 주기적 신호를 Coordinator로 전송하여 장애 여부 판단 • Session Time, Poll(데이터 요청) Time 시간을 확인 Consumer 장애 시 Partition 재할당 • Consumer의 신호가 없으면 장애로 판단하고, partition 재 할당 • JMX Metric의 Join 발생 Broker (Coordinator) Partition-1 Consumer-1 Consumer-2 Consumer-3 Broker Broker Partition-2 Partition-3 Consumer-Group Broker (Coordinator) Partition-1 Consumer-1 Consumer-2 Consumer-3 Broker Broker Partition-2 Partition-3 Consumer-Group Time Out
- 27. 27 확장 시점 언제 클러스터를 확장해야 할까?
- 28. 28 Producer Consumer Broker Broker Broker ü 과도한 부하가 발생하는 구간이 어디인가? (NW, CPU, Memory) ü Broker 처리 성능이 저하되고 있는가? 확장성을 위해 확인해야 할 Metrics 유형은? 네트워크 부하 처리시간 증가 대기 시간 증가
- 29. 29 Broker 서버 자원의 상태를 예측하는 Metrics https://blog.serverdensity.com/how-to-monitor-kafka/ Metric Comments 대응 RequestsPerSec • 너무 많은 요청으로 Broker의 네트워크 대역폭을 지속 초과하면, • Broker를 확장하여 분산 처리 필요 • (kafka.network: type=RequestMetrics) LogFlushRateAndTimeMs • Cache에 저장된 데이터를 Log(Disk)로 저장하는 비율 • 비율이 점차 늦어진다면, • Broker를 추가하여 partition에 쓰는 부하를 분산 필요 • (kafka.log:type=LogFlushStats) 지연 발생시, 데이터 유실 가능성 높음 ErrorsPerSec • 즉, Network Error가 없는 상태에서 Broker 처리량이 줄어든다면, • Broker 내부 자원 부족 가능성 높음 • (kafka.network: type=RequestMetrics) Broker Metrics
- 30. 30 자신의 운영 시스템에 최적화된 모니터링 지표의 조합이 가장 중요
- 31. 31 END