Writing and testing high frequency trading engines in java
66 likes35,392 views

The document details the design and implementation of a high-frequency trading engine using Java, focusing on achieving low latency and high throughput. Key concepts include event-driven architecture, low garbage collection practices, and efficient memory management, highlighting the importance of minimizing operational delays and understanding latency profiles. The use of specialized libraries such as OpenHFT is emphasized for achieving optimal performance in trading applications.



































![How does it perform?
On this laptop
[GC 15925K->5838K(120320K), 0.0132370 secs]
[Full GC 5838K->5755K(120320K), 0.0521970 secs]
Started
processed 0
processed 1000000
Processed 2000000
… deleted …
processed 9000000
processed 10000000
Received 10000000
Processed 10,000,000 events in and out in 20.2 seconds
The latency distribution was 0.6, 0.7/2.7, 5/26 (611) us for the
50, 90/99, 99.9/99.99 %tile, (worst)
On an i7 desktop
Processed 10,000,000 events in and out in 20.0 seconds
The latency distribution was 0.3, 0.3/1.6, 2/12 (77) us for the
50, 90/99, 99.9/99.99 %tile, (worst)](https://image.slidesharecdn.com/writingandtestinghighfrequencytradingenginesinjava-130926073124-phpapp02/85/Writing-and-testing-high-frequency-trading-engines-in-java-37-320.jpg)

Writing and testing high frequency trading engines in java
- 1. Writing and Testing Higher Frequency Trading Engine Peter Lawrey Higher Frequency Trading Ltd
- 2. Who am I? Australian living in UK. Father of three 15, 9 and 6 “Vanilla Java” blog gets 120K page views per month. 3rd for Java on StackOverflow. Six years designing, developing and supporting HFT systems in Java for hedge funds, trading houses and investment banks. Principal Consultant for Higher Frequency Trading Ltd.
- 3. Event driven determinism Critical operations are modelled as a series of asynchronous events Producer is not slowed by the consumer Can be recorded for deterministic testing and monitoring Can known the state for the cirtical system without having to ask it.
- 4. Transparency and Understanding Horizontal scalability is valueable for high throughput. For low latency, you need simplicity. The less the system has to do the less time it takes.
- 5. Productivity For many systems, a key driver is; how easy is it to add new features. For low latency, a key driver is; how easy is it to take out redundant operations from the critical path.
- 6. Layering Traditional design encourages layering to deal with one concept at a time. A driver is to hide from the developer what the lower layers are really doing. In low latency, you need to understand what critical code is doing, and often combine layers to minimise the work done. This is more challenging for developers to deal with.
- 7. Taming your system Ultra low GC, ideally not while trading. Busy waiting isolated critical threads. Giving up the CPU slows your program by 2-5x. Lock free coding. While locks are typically cheap, they make very bad outliers. Direct access to memory for critical structures. You can control the layout and minimise garbage.
- 8. Latency profile In a complex system, the latency increases sharply as you approach the worst latencies.
- 9. Latency In a typical system, the worst 0.1% latency can be ten times the typical latency, but is often much more. This means your application needs to be able to track these outliers and profile them. This is something most existing tools won't do for you. You need to build these into your system so you can monitor production.
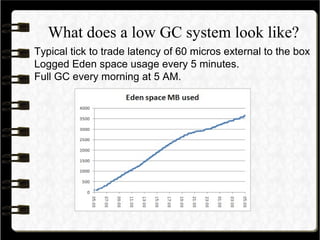
- 10. What does a low GC system look like? Typical tick to trade latency of 60 micros external to the box Logged Eden space usage every 5 minutes. Full GC every morning at 5 AM.
- 11. Low level Java Java the language is suitable for low latency You can use natural Java for non critical code. This should be the majrity of your code For critical sections you need a subset of Java and the libraires which are suitable for low latency. Low level Java and natural Java integrate very easily, unlike other low level languages.
- 12. Latency reporting ● Look at the percentiles, typical, 90%, 99%, 99.9% and worse in sample. ● You should try to minimise the 99% or 99.9%. You should look at the worst latencies for acceptability.
- 13. Latency and throughput ● There are periodic disturbances in your system. This means low throughput sees all of these. ● In high throughput systems, the delays not only impact one event, but many events, possibly thousands. ● Test realistic throughputs for your systems, as well as stress tests.
- 14. Why ultra low garbage ● When a program accesses L1 cache is about 3x faster than using L2. L2 is 4 to 7 times faster than accessing L3. L3 is shared between cores. One thread running in L1 cache can be faster than using all your CPUs at once using L3 cache. ● You L1 cache is 32 KB, so if you are creating 32 MB/s of garbage you are filling your L1 cache with garbage every milli-second.
- 15. Recycling is good Recycling mutable objects works best if; They replace short or medium lived immutable objects. The lifecycle is easy to reason about. Data structure is simple and doesn't change significantly. These can help eliminate, not just reduce GCs.
- 16. Avoid the kernel The kernel can be the biggest source of delays in your system. It can be avoided by ● Kernel bypass network adapters ● Isolating busy waiting CPUs ● Memory mapped files for storage.
- 17. Avoid the kernel Binding critical, busy waiting threads to isolated CPUs can make a big difference to jitter. Count of interrupts per hour by length.
- 18. Lock free coding Minimising the use of lock allows thread to perform more consistently. More complex to test. Useful in ultra low latency context Will scale better.
- 19. Faster math Use double with rounding or long instead of BigDecimal ~100x faster and no garbage Use long instead of Date or Calendar Use sentinal values such as 0, NaN, MIN_VALUE or MAX_VALUE instead of nullable references. Use Trove for collections with primitives.
- 20. Low latency libraries Light weight as possible The essence of what you need and no more Designed to make full use of your hardware Performance characteristics is a key requirement.
- 21. OpenHFT project ● Thread Affinity binding OpenHFT/Java-Thread-Affinity ● Low latency persistence and IPC OpenHFT/Java-Chronicle ● Data structures in off heap memory OpenHFT/Java-Lang ● Runtime Compiler and loader OpenHFT/Java-Runtime-Compiler Apache 2.0 open source.
- 22. Java Chronicle ● Designed to allow you to log everything. Esp tracing timestamps for profiling. ● Typical IPC latency is less than one micro-second for small messages. And less than 10 micro-seconds for large messages. ● Support reading/writing text and binary.
- 23. Java Chronicle performance ● Sustained throughput limited by bandwidth of disk subsystem. ● Burst throughput can be 1 to 3 GB per second depending on your hardware ● Latencies for loads up to 100K events per second stable for good hardware (ok on a laptop) ● Latencies for loads over one million per second, magnify any jitter in your system or application.
- 24. Java Chronicle Example Writing text int count = 10 * 1000 * 1000; for (ExcerptAppender e = chronicle.createAppender(); e.index() < count; ) { e.startExcerpt(100); e.appendDateTimeMillis(System.currentTimeMillis()); e.append(", id=").append(e.index()); e.append(", name=lyj").append(e.index()); e.finish(); } Writes 10 million messages in 1.7 seconds on this laptop
- 25. Java Chronicle Example Writing binary ExcerptAppender excerpt = ic.createAppender(); long next = System.nanoTime(); for (int i = 1; i <= runs; i++) { double v = random.nextDouble(); excerpt.startExcerpt(25); excerpt.writeUnsignedByte('M'); // message type excerpt.writeLong(next); // write time stamp excerpt.writeLong(0L); // read time stamp excerpt.writeDouble(v); excerpt.finish(); next += 1e9 / rate; while (System.nanoTime() < next) ; }
- 26. Java Chronicle Example Reading binary ExcerptTailer excerpt = ic.createTailer(); for (int i = 1; i <= runs; i++) { while (!excerpt.nextIndex()) { // busy wait } char ch = (char) excerpt.readUnsignedByte(); long writeTS = excerpt.readLong(); excerpt.writeLong(System.nanoTime()); double d = excerpt.readDouble(); }
- 27. Java Chronicle Latencies 500K/second Took 10.11 seconds to write and read 5,000,000 entries Time 1us: 1.541% 3us: 0.378% 10us: 0.218% 30us: 0.008% 100us: 0.002% 1 million/second Took 5.01 seconds to write and read 5,000,000 entries Time 1us: 3.064% 3us: 0.996% 10us: 0.625% 30us: 0.147% 100us: 0.105% 2 million/second Took 2.51 seconds to write and read 5,000,000 entries Time 1us: 7.769% 3us: 3.836% 10us: 2.943% 30us: 1.865% 100us: 1.798% 5 million/second Took 1.01 seconds to write and read 5,000,000 entries Time 1us: 37.039% 3us: 27.926% 10us: 23.635% 30us: 21% 100us: 21%
- 28. How does it perform With one thread writing and another reading Chronicle 2.0.1 -Xmx32m Tiny 4 B Small 16 B Medium 64 B Large 256 B tmpfs 77 M/s 57 M/s 23 M/s 6.6 M/s ext4 65 M/s 35 M/s 12 M/s 3.2 M/s
- 29. Java Affinity ● Designed to help reduce jitter in your system. ● Can reduce the amount of jitter if ~50 micro-seconds is important to you. ● Only really useful for isolated cpus ● Understands the CPU layout so you can be declaritive about your requirement.
- 30. Java Lang ● Suports allocation and deallocation of 64-bit sized off heap memory regions ● Thread safe data structures. ● Fast low level serialization and deserialization ● Wraps Unsafe to make it safer to use, without losing to much performance.
- 31. Java Runtime Compiler ● Wraps the Compiler API so you can compile in memory from a String and have the class loaded ● Supports writing the text to a directory which in debug mode allowing you to step into generated code. ● Generate Java code is slower but easier to read/debug than generated byte code ● Dependency injection from Java is easier to debug and profile than XML
- 32. Higher level interface Instead of serializing raw messages, you can abstract this functionality with asynchonous interfaces. You have one or more interfaces which describe all the messages into the system and all the messages out of the system. You can test the processing engine without any queuing/transport layers.
- 33. An example An interface for messages inbound. An interface for messages outbound. All messages via persisted IPC.
- 34. Is there a higher level API? The interfaces look like this public interface Gw2PeEvents { public void small(MetaData metaData, SmallCommand command); } public interface Pe2GwEvents { public void report(MetaData metaData, SmallReport smallReport); }
- 35. Is there a higher level API? The processing engine class PEEvents implements Gw2PeEvents { private final Pe2GwWriter pe2GwWriter; private final SmallReport smallReport = new SmallReport(); public PEEvents(Pe2GwWriter pe2GwWriter) { this.pe2GwWriter = pe2GwWriter; } @Override public void small(MetaData metaData, SmallCommand command) { smallReport.orderOkay(command.clientOrderId); pe2GwWriter.report(metaData, smallReport); } }
- 36. Demo An interface for messages inbound. An interface for messages outbound. All messages via persisted IPC.
- 37. How does it perform? On this laptop [GC 15925K->5838K(120320K), 0.0132370 secs] [Full GC 5838K->5755K(120320K), 0.0521970 secs] Started processed 0 processed 1000000 Processed 2000000 … deleted … processed 9000000 processed 10000000 Received 10000000 Processed 10,000,000 events in and out in 20.2 seconds The latency distribution was 0.6, 0.7/2.7, 5/26 (611) us for the 50, 90/99, 99.9/99.99 %tile, (worst) On an i7 desktop Processed 10,000,000 events in and out in 20.0 seconds The latency distribution was 0.3, 0.3/1.6, 2/12 (77) us for the 50, 90/99, 99.9/99.99 %tile, (worst)
- 38. Q & A Blog: Vanilla Java Libraries: OpenHFT [email protected]