
 Data Structure
Data Structure Networking
Networking RDBMS
RDBMS Operating System
Operating System Java
Java MS Excel
MS Excel iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C Programming
C Programming C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
What is XmlPath in Rest Assured?
We can find all XML nodes with Rest Assured using the XMLPath. If the response is in XML format, we need to use the methods under the XMLPath. If the value of the node is an integer, we have to use the method getInt.
If the value of the node is a string we have to use the method getString and if the values are in a list, we can obtain its value with the getList method. We shall first send a GET request via Postman on a mock API URL.

Using Rest Assured, we shall validate its XML Response containing the name of the subjects Rest Assured, Postman, and their prices 10 and 6 respectively.
In the above XML Response, we can obtain the values of the author and pages nodes by traversing the paths - books.book.author and books.book.pages respectively.
Example1
Code Implementation
import org.testng.annotations.Test;
import static io.restassured.RestAssured.*;
import io.restassured.RestAssured;
import io.restassured.http.ContentType;
import io.restassured.path.xml.XmlPath;
public class NewTest {
@Test
void getXMLNodes() {
//base URI with Rest Assured class
RestAssured.baseURI = "https://run.mocky.io/v3";
//accept XML CONTENT as String
String r = given().accept(ContentType.XML).when()
//GET request
.get("/c1d5e067-212d-4f63-be0db51751af1654")
.thenReturn().asString();
//object of XmlPath class
XmlPath x = new XmlPath(r);
//get nodes by traversing node paths
System.out.println("Author name: " + x.getString("books.book.author"));
System.out.println("Pages: " + x.getString("books.book.pages"));
}
}
Output

We can check HTML documents with REST Assured using the methods of XMLPath. We shall first send a GET request via Postman on an endpoint and go through the Response body. In the below image, it is seen that the title value obtained is About Careers at Tutorials Point - Tutorialspoint.
Endpoint − https://www.tutorialspoint.com/about/about_careers.htm.
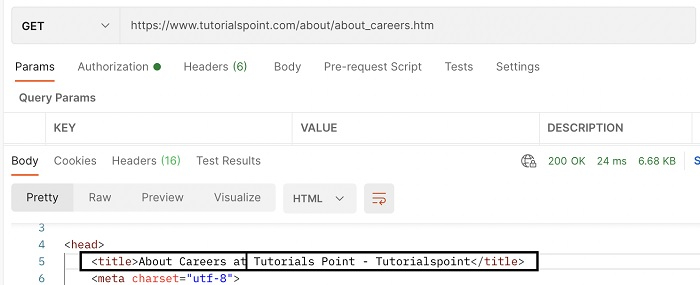
To obtain the html content from Response, we shall use the method contentType(ContentType.HTML).extract(). Then convert the Response body obtained to string. Finally, we shall get the page title with the method html.head.title.
Example2
Code Implementation
import static io.restassured.RestAssured.given;
import static io.restassured.path.xml.XmlPath.CompatibilityMode.HTML;
import static org.testng.Assert.assertEquals;
import org.testng.annotations.Test;
import io.restassured.http.ContentType;
import io.restassured.path.xml.XmlPath;
import io.restassured.response.Response;
public class NewTest {
@Test
public void verifyHtml() {
//extract HTML response from endpoint
Response r = given()
.when()
.get("https://www.tutorialspoint.com/about/about_careers.htm")
.then().contentType(ContentType.HTML).extract()
.response();
//convert xml body to string
XmlPath p = new XmlPath(HTML, r.getBody().asString());
//obtain html page title
System.out.println(p.getString("html.head.title"));
//verify title with assertion
assertEquals(p.getString("html.head.title"), "About Careers at Tutorials Point - Tutorialspoint");
}
}
Output


4K+ Views
